

It’s no secret that many websites use RSS feed scrapers to steal content from other websites. Unfortunately, it’s become all too commonplace for content creators to find their work stolen and shared without their permission or even credit. Here we find out how to stop them.
That’s why we have compiled a list of illegal RSS feed copyright scrapers, so that content creators can be aware of the sites that are stealing their work and take steps to protect their content.
These scrapers are not limited to any particular type of website. They can be used to extract content from any website that hosts RSS feeds, including news sites, blogs, and social media sites.
The scrapers collect the content from the RSS feeds and then republish it on their own website, often without permission from the original content creator. This can be damaging to the content creator, as it not only deprives them of potential revenue, but also hurts their reputation as a content creator.
When it comes to combating illegal rss feed content scrapers, the best solution is to report them to relevant bodies such as the DMCA and your hosting provider
This list will continue to be updated as more are detected. It’s also highly recommend you use tools and services such as “Cloudflare” and “WordFence” to detect and block the these domains from stealing your content.
It’s also recommend you refrain from visiting these websites after you have detected them as some may contain malware.
How to protect your RSS feeds from scrapers using Cloudflare.
You can use Cloudflare to protect your RSS feed URLs by creating the follwing web application firewall rules (WAF) This is a great method if you don’t wish to disable your RSS feeds completly and allow some resources to come in.
Note – Depending on your website type, configuration and setup some changes to this WAF security rule may be required. If unsure you can consult with Cloudflare’s documentation or ask a question in Cloudflare’s community forums. (use this WAF rule at your risk)
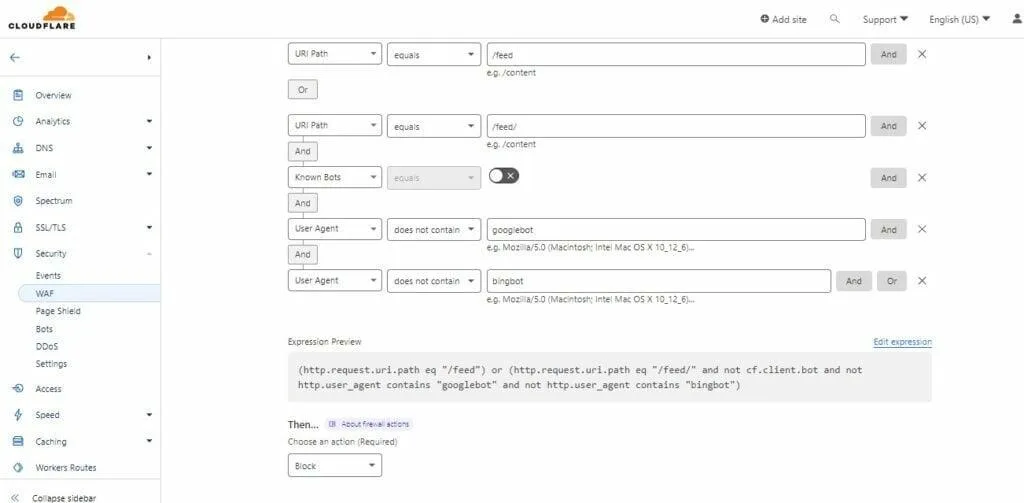
You can either manually create the above WAF rule or simply enter the following expression via a copy and paste into Cloudflare’s handy expression builder.
(http.request.uri.path eq “/feed”) or (http.request.uri.path eq “/feed/” and not cf.client.bot and not http.user_agent contains “googlebot” and not http.user_agent contains “bingbot”)
You can also create a custom WAF rule to block only certain user agents used to scrape your website content for the purpose reproduction without your permission.
It also worth noting, offenders desperate to bypass the features of Cloudlfare’s WAF can use sophisticated methods and hacking tools. Although this extreamly rare and requires a very high skill set, it’s knowledge most copyright offenders and scraper bot operators don’t have.
In the rare situation of hackers bypassing cloud based firewalls and/or obtaining your website’s IP address, many hosting providers that use the well known cPanel solution for hosting servers provide a server side security plugin called Modsec (Mod Security™ ) at no cost.
This also allows you to block or allow selected user agents from accessing site data and content. However, at the server level as opposed to a cloud based firewall such as Cloudflare.
Both Cloudflare and server side security solutions such as Modsec also provide great overall site protection from all kinds of nasty internet critters.
Expression – WAF Rule Use Disclaimer. | Considerations
The mentioned rule may cause undesired results depending on your RSS feed requirements, configuration and use cases. In the case you might want to allow certain websites, user agents, bots and RSS feed readers to access your RSS feeds, you will need to make some changes to the expression. Some examples of this are:
Google Feedburner.
Google’s feedfetcher grabs RSS or Atom feeds when users choose to add them to their Google homepage or Google Reader.
Feedfetcher also collects and periodically refreshes these user-initiated feeds, but does not index them in Blog Search or Google’s other search services (feeds only appear in their search results if they’ve been crawled by Googlebot).
Common Feed Readers
RSS Readers also known as news aggregators, feed aggregators, or feed readers, is a software that collects and combines content from multiple sources to display it in one place for easy viewing.
For Google News Approved Sites – Instant Indexing APIs Via RSS
For those with Google News approved websites, you will need to “allow” the follwing user agents in order for the search engine to see your feed URLs for instant indexation. Otherwise, it will be blocked.
| Full user agent string | APIs-Google (+https:/ |
| Full user agent string | FeedFetcher-Google; (+http:/ |
How to totally disable RSS feeds directly from your CMS
You can also totally disable your RSS feed via common content management systems such as WordPress via the functions.php file
- From your WordPress theme, download and open functions.php file in a text editor
- Paste the below given code snippet in it and upload the file back.
function wp_disable_feeds() {
wp_die( __('No feeds available!') );
}
add_action('do_feed', 'wp_disable_feeds', 1);
add_action('do_feed_rdf', 'wp_disable_feeds', 1);
add_action('do_feed_rss', 'wp_disable_feeds', 1);
add_action('do_feed_rss2', 'wp_disable_feeds', 1);
add_action('do_feed_atom', 'wp_disable_feeds', 1);
add_action('do_feed_rss2_comments', 'wp_disable_feeds', 1);
add_action('do_feed_atom_comments', 'wp_disable_feeds', 1);Citing the source – Common myth reviled
Many RSS feed scraper website owners and blog operators believe that citing the source of the content they have removed and reproduced removes them from being in breach of copyright. This is entirely untrue and incorrect.
Major search engines don’t offically “penalise” websites for containing duplicte or exact match content so this is something RSS feed scraper operators count and bank on. Before scraping or aggregating website or news content you are required to obtain reproduction rights and permision from the original source.
Attorney for Business Owners Arron Hall says under the law, each copy must be authorised to avoid copyright infringement.
“From a U.S. copyright law perspective, you must get permission to avoid copyright infringement. and the only way to avoid copyright infringement is to have the owner’s consent to make a copy.”
The website authority problem hurting legitimate publishers
So, you decided to take the very rewarding plunge and build your own informative website, blog or news publication. That’s great! But ranking it is hard right?
It is thought that search engines base the position of a website or article in search listings according to over 200 ranking factors.
While many of these factors are known to be more important and carry more weight than others, one of the major insights search engines use is based on an algorithimc measurement called inbound ‘Hyperlinks” and “Referring Domains.”
Generally speaking, seach engines will promote or “rank’ an article higher in search engine results based on the website’s ‘Overall” authority.
According to many trusted search engine optimisation (SEO) publications and blogs a website with a higher authority as a result of having a higher number of quality inbound hyperlinks (otherwise known as votes or endorsements) will have a much better chance of being placed higher in search results. (not in all cases due to many other variables)
This means, a young website publishing high quality content can have its content removed/stolen and republished on another website that is more mature and has a higher authority.
Of course this often results in the original publishers content being ranked higher on someone elses website and leaving the original content creator behind.
Even worse, the offending website can be awarded with votes/endorsements (hyperlinks) which then gives the copyright website even more authority and the original publisher is basically stripped of the trophy they should have been awarded.
This happens far to often and is making it almost impossibe for many new publishers to build up there own website authority. Yes. you can make a DMCA takedown request. However, by then it’s far to late because the hyperlink that should have been awarded to you is referncing the offenders website.
Of course, you can contact the website owner to inform they have assigned the wrong website (a copycat) the hyperlink reference and also write out a DCMA takedown request. However, all this takes a lot of time and effort, leaving you with constantly chasing these issues down and leaving you no time left to focus on your content production.
Also, 8 times out of 10 the publication that referenced the copycat instead of your website is either not contactable, won’t reply or won’t edit the hyperlink to reference your original.
All this leaves you with basically only one option. Totally block or dont publish an RSS feed on your website at all. Or at least until your own website has matured in age and gained trust, authority and a better inbound hyperlink profile.
Rule of thumb : Don’t open, publish or advertise an RSS feed on your website until your “Domain Rating” according to well known (one of the better ones) “Ahrefs” SEO metrics score (DR) has reached a minium of DR-15. 90% of RSS feed scraper/unauthorised reproduction sites don’t exceed this metric.
(Note, SEO metrics scores are almost never a direct correlation of your website’s true authority and only use these tools as a very rough guideline)
‘Most RSS feed scrapers have very low domain authority. So it’s also recommended you dont open or advertise an RSS feed on your website until it’s at least 12 months old and gained some good inbound hyperlink references from high quality and trusted sources.
This will help stop the scraper sites outranking you in the search engines with your own content, research and well earned hard work.
Concluding
As content is key to the success of any business, there is a very real threat of scraper websites stealing your business, content and damanging your well earned reputation.
We hope this article will help you detect and stop RSS feed scraper websites, the bots behind them and allow you to concerntrate on producing quality content for the internet community to enjoy and hopefully send you a vote!





